导读
本文适合知道NUMA这个词但想进一步了解的新手。
以下的文章内容包括:NUMA的产生背景,NUMA的架构细节和几个上机演示的例子。
NUMA的诞生背景
在NUMA出现之前,CPU朝着高频率的方向发展遇到了天花板,转而向着多核心的方向发展。
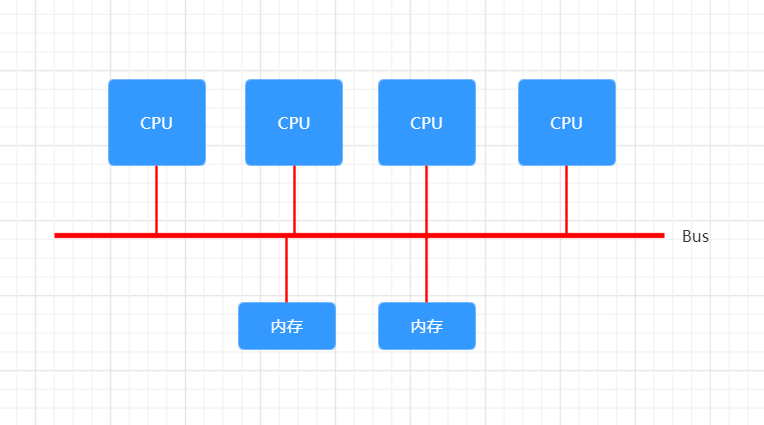
在一开始,内存控制器还在北桥中,所有CPU对内存的访问都要通过北桥来完成。此时所有CPU访问内存都是“一致的”,如下图所示:
NUMA构架细节
NUMA 全称 Non-Uniform Memory Access,译为“非一致性内存访问”。这种构架下,不同的内存器件和CPU核心从属不同的 Node,每个 Node 都有自己的集成内存控制器(IMC,Integrated Memory Controller)。
在 Node 内部,架构类似SMP,使用 IMC Bus 进行不同核心间的通信;不同的 Node 间通过QPI(Quick Path Interconnect)进行通信,如下图所示:

在Linux中,对于NUMA有以下几个需要注意的地方:
- 默认情况下,内核不会将内存页面从一个 NUMA Node 迁移到另外一个 NUMA Node;
- 但是有现成的工具可以实现将冷页面迁移到远程(Remote)的节点:NUMA Balancing;
- 关于不同 NUMA Node 上内存页面迁移的规则,社区中有依然有不少争论。
对于初次了解NUMA的人来说,了解到这里就足够了,本文的细节探讨也止步于此,如果想进一步深挖,可以参考开源小站这篇文章。
上机演示
NUMA Node 分配
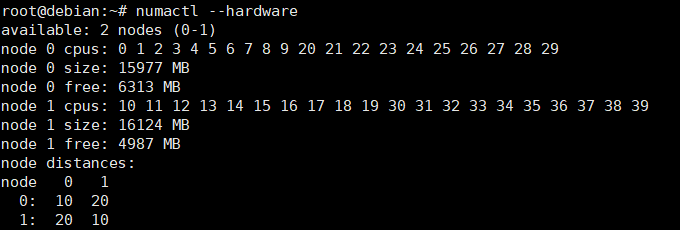
NUMA Node 绑定
Node 和 Node 之间进行通信的代价是不等的,同样是 Remote 节点,其代价可能不一样,这个信息在 node distances 中以一个矩阵的方式展现。

NUMA 状态